
Grafana
- Canonical Observability
| Channel | Revision | Published | Runs on |
|---|---|---|---|
| latest/stable | 117 | 10 Sep 2024 | |
| latest/candidate | 117 | 28 Jun 2024 | |
| latest/beta | 117 | 21 Jun 2024 | |
| latest/edge | 121 | 18 Oct 2024 | |
| 1.0/stable | 93 | 12 Dec 2023 | |
| 1.0/candidate | 93 | 22 Nov 2023 | |
| 1.0/beta | 93 | 22 Nov 2023 | |
| 1.0/edge | 93 | 22 Nov 2023 |
juju deploy grafana-k8s
Deploy Kubernetes operators easily with Juju, the Universal Operator Lifecycle Manager. Need a Kubernetes cluster? Install MicroK8s to create a full CNCF-certified Kubernetes system in under 60 seconds.
Platform:
With grafana, we can visually display a subset of our metrics and logs, using dashboards and panels. To a large degree this is a matter of experience and taste. The purpose of this document is to outline best practices for creating Grafana dashboards that look, feel, and behave in a consistent way across all charms and projects that integrate with the Canonical Observability Stack.
Charmed dashboards are packed together with their target charm, and are automatically listed in grafana once related to grafana. For this reason, the target audience of dashboards is e.g. an on-caller you have never met.
Principles
A dashboard should tell a story or answer a question
Every dashboard panel should add insight to the question posed by the dashboard’s title.
A dashboard should have a clear goal and purpose. If you cannot concisely formulate your dashboard’s reason for existence, it is very likely that it’s not serving a purpose for anyone. As a side note: It’s convenient is not a valid goal.
A dashboard should reduce the cognitive load, not add to it
A newly created dashboard makes sense to the author, but it should also make sense to the author a year from creating the dashboard, as well as to new eyes.
A dashboard should be tailored to the audience looking at it
Who is the primary audience of your dashboard? Depending on who you’re targeting, your dashboard is likely going to look very different. Trying to cater to all of these personas in a single dashboard is most likely going to result in a dashboard that does not provide any value to either. Instead of combining multiple purposes into a single dashboard, consider splitting it into multiple linked dashboards.
Some examples of common dashboard personas:
The Site Reliability Engineer
Looking to surface, pinpoint, and analyze a problem that is occurring in a production environment. This persona likely has a high level of general technical understanding but not necessarily about the inner workings of the system being observed. Not likely to be interested in the commercial consequences of the problem.
The System Administrator
Similar to the Site Reliability Engineer in purpose and technical aptitude, but likely to be more focused on the inner workings of the system than the infrastructure it is running on.
The Customer
Wants to know whether there is a problem and whether the system is still within the boundaries of the commercial service level agreements. Likely not too interested in the technical details but in the commercial consequences of the problem.
The charm author
Wants to know:
- Does a different workload version have a considerable impact on resource utilization?
- Does a particular opinionated config change have an impact on performance?
Actionable advice
Use a top-down approach
Go from general to specific. Should be applied both globally and per row. What is most interesting or useful for the intended audience? Keep that as far up as possible in your dashboard.
Use explanations liberally
As someone building a dashboard, it’s easy to walk into the trap of thinking that what’s being visualized will be as obvious to the user as it is to you. Unless you are the only one who will ever use the dashboard, this is almost entirely certain to not be the case.
For “power users” that already have the context, instructions and explanations can be easily discarded while looking at the dashboard. For new users, it will be paramount for their understanding.
Don’t hide vital information in links, or tooltips that require hovering to be revealed.
Use rows to group information
- Separate dashboards for the host system and the application.
- Separate rows for cpu, storage, network, etc.
Use clear time series labels
Make sure that each time series label is as unambiguous as possible by including just the right amount of information to make it stand out as unique and descriptive.
Use the right visualization for the right metric
HTTP status codes

A good way to display HTTP status codes visually can be the State Timeline plugin, which allows to immediately grasp possibly time-related network issues.
Data rates

Time Series visualizations are generally effective for data rates
-
Using aggregations like min, max, avg, and mean can be very useful.
-
Sometimes it makes sense to set log-scale for the y axis.
-
Sometimes, you might be interested in how fast the data rate is increasing/decreasing instead of the actual rate: in that case, it would make sense to use a derivative in the expression.
API request latency
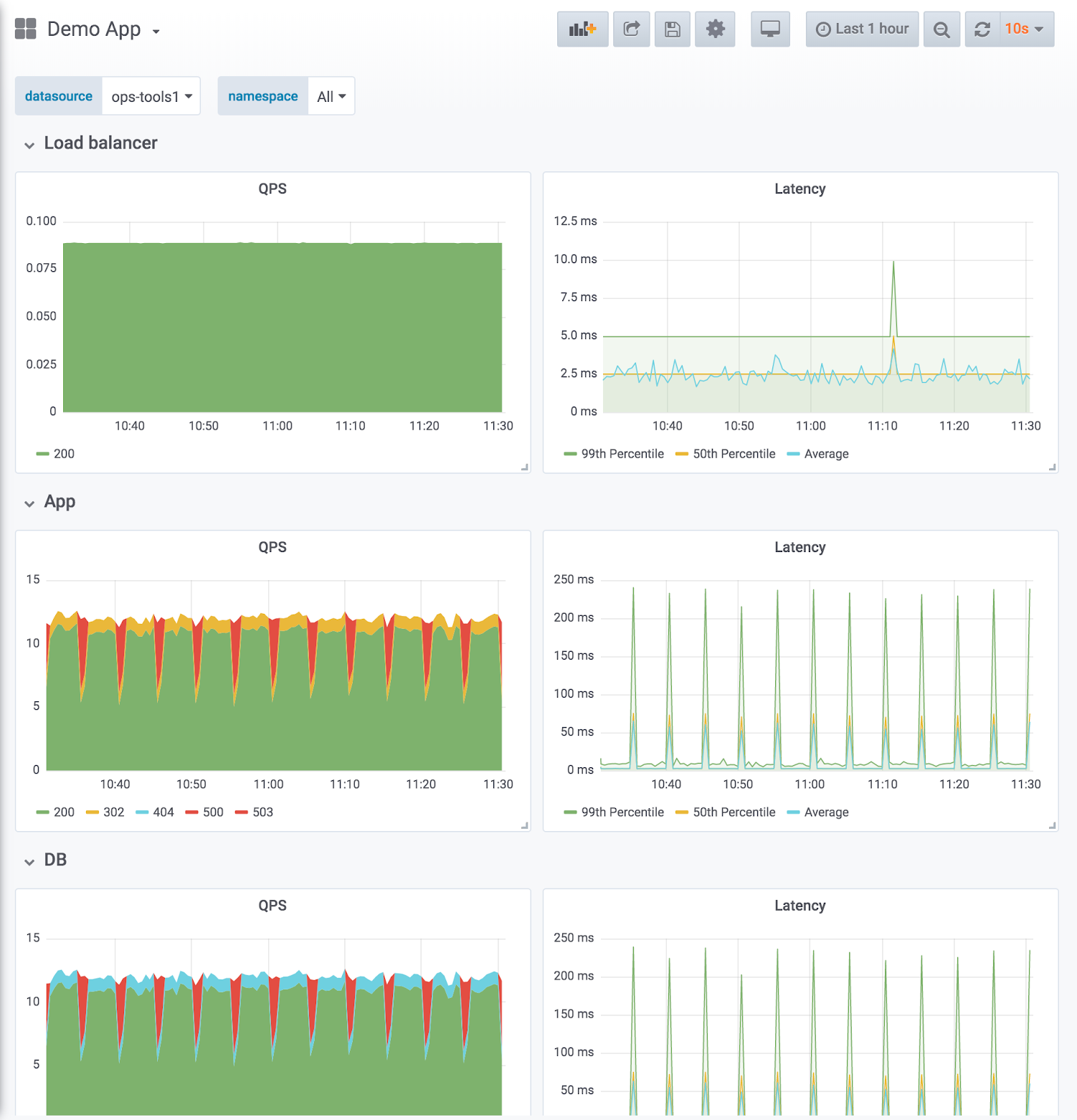 (image from the Grafana dashboard best practices)
(image from the Grafana dashboard best practices)
For latency, it’s often more interesting to visualize aggregated data: specifically, quantiles are extremely flexible and allow you to better contextualize latency issues:
- the 99th Percentile indicates what latency most requests fall under; it’s useful to cut off uninteresting spikes;
- the 50th Percentile is the median latency, useful as a more robust indicator of the average latency of a request.
Different quantiles are useful for different use cases (10th Percentile, 90th Percentile and 95th Percentile are also commonly used).
Most common error types
- Accumulated, reverse-sorted.

Address SLOs
Refs:
- https://www.oreilly.com/library/view/implementing-service-level/9781492076803/
- GitHub - slok/sloth: 🦥 Easy and simple Prometheus SLO (service level objectives) generator
Provide ways to dig deeper
If there is another dashboard that allows the user to have a deeper look into the issue, provide a link to it. If there is a helper query that can help in getting more information that doesn’t fit well into an overview provided with a dashboard, add a link to the query.
Example: a service overview might show a panel with cache status that could link to a separate cache dashboard with more metrics.
Combine different telemetry types
Dashboards don’t have to be only about the metrics. In cases when the user has access to more than one telemetry type (metrics, logs, traces) often it makes sense to combine them together in a single dashboard. An example could be “recent longest queries” showing the longest running traces from the dashboard timespan. Different telemetry types add different context that can be helpful as long as it fits the same dashboard story.
Use an effective naming scheme
When making your dashboard, you should choose a good name that summarizes its contents.
Dashboards are identified by their UID; it’s a good practice to set it by following the format {charm_name}-{dashboard_codename}-{revision_number} (staying within the 40 characters limit). If you make changes to your dashboard, you should always change the title and UID as well, to avoid collisions with previous versions.
Checklist for dashboard composition
- Manually review all the metrics the workload exposes and decide which could be used to reflect potential failure modes. Use them for panels.
- The dashboard and all panels have an intro text box explaining why the dashboard/panel is important, and what to look for. Top row has introduction/declaration of purpose.
Checklist for template variables
- Use query variables in variables so that dropdowns are automatically populated by grafana. For example, “label values” extracts all the values a given label has. This approach is likely better than a free-text regex match.
- Ideally (but not necessary), all dropdowns should be applicable to all panels in the dashboard. It may be confusing if changes in dropdown selection do not affect some panels.
Checklist for panel design
- Both X and Y axis have labels.
- Standard panels are used for:
- HTTP status codes and endpoint latency.
- 50, 95 and 99 percentiles.
- Panel legend is dynamic and aggregated correctly (e.g. using aggregation operators
by,without). Keep in mind multi-app multi-unit deployments. - Panel threshold for green/red is correctly set (or disabled).
Example production grade grafana instances
References
- Grafana Dashboard Best Practices
- Grafana dashboards: A complete guide to all the different types you can build
- Google SRE Book